・お題:欠損値を補完したい。
・前回、主にpandasを用いて欠損値を数えたり削除したり何らかの定数で補完する方法を少し調べた。
・今回は、scikit-learnでもうちょっと頑張って欠損値を補完したい。
・とりあえず、データセットを作る。
import pandas as pd
import numpy as np
import random
a=np.random.rand(1000)
b=[i + np.random.normal(0,0.1) for i in a]
c=[i*(-1.3) + np.random.normal(0,0.2) for i in a]
df=pd.DataFrame({"A":a,"B":b,"C":c})
・dfの中身は以下の通り。Aは0-1の乱数。BはAに正規分布の乱数を加えた数。CはAを-1.3倍して正規分布の乱数を加えた数。それぞれ1000個ずつ数字が入っている。

・次に、欠損を持つデータフレームdf2を作成する。
df2=df.copy()
mask=np.random.choice([0,1],p=[0.1,0.9],size=df2.shape[0]*df2.shape[1]).reshape(df2.shape[0],df2.shape[1]).astype(bool)
df2=df2.where(mask, np.nan)
df2.info()
出力は、
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 899 non-null float64
1 B 897 non-null float64
2 C 903 non-null float64
dtypes: float64(3)
memory usage: 23.6 KB
になる。どの列も1割程度を欠損している。
・scikit-learnを用いた補完は以下の記事を参考にさせて頂いた。詳しいことはリンク先の記事をご参照いただきたい。
#デフォルトで補完してみる
from sklearn.experimental import enable_iterative_imputer#これがないと下のコマンドが走らなかった。
from sklearn.impute import IterativeImputer
df2_DefHokan = pd.DataFrame(IterativeImputer().fit_transform(df2))
df2_DefHokan.info()
出力は以下。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 1000 non-null float64
1 1 1000 non-null float64
2 2 1000 non-null float64
dtypes: float64(3)
memory usage: 23.6 KB
non-nullが1000個なので、補完されたっぽい。
#k-nnで補完してみる。
from sklearn.impute import KNNImputer
df2_KnnHokan = pd.DataFrame(KNNImputer(n_neighbors=3).fit_transform(df2))
#ランダムフォレスト回帰で補完してみる。
from sklearn.ensemble import RandomForestRegressor
df2_RfHokan=pd.DataFrame(IterativeImputer(RandomForestRegressor()).fit_transform(df2))
・ここまででそれぞれの手法で欠損値を補完したデータフレームを作成したことになる。実際どんな感じで補完されたのか、ちょっと見てみたい。以降の処理で、欠損させる前のデータ(df)の補完対象となったデータと、それぞれの手法で補完されたデータを突き合わせ、どんな感じか見てみる。
Kesson=df2.isna()
#とりあえず列Aの変数がどう補完されたか見てみたい。A列を取り出して、一つのDataFrameにまとめて、seabornのpairplotに投げる。
ori_A=df.iloc[:,0][Kesson.iloc[:,0]]
DefHokan_A=df2_DefHokan.iloc[:,0][Kesson.iloc[:,0]]
KnnHokan_A=df2_KnnHokan.iloc[:,0][Kesson.iloc[:,0]]
RfHokan_A=df2_RfHokan.iloc[:,0][Kesson.iloc[:,0]]
Hokan_A=pd.DataFrame({"ori_A":ori_A,"DefHokan_A":DefHokan_A,"KnnHokan_A":KnnHokan_A,"RfHokan_A":RfHokan_A})
import seaborn as sns
sns.pairplot(Hokan_A)
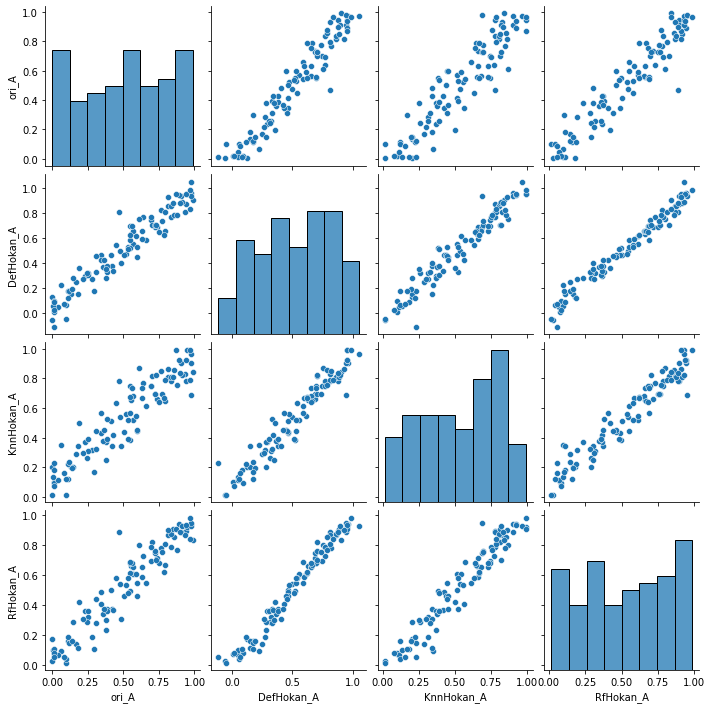
・ori_Aとそれぞれの手法で補完したAを散布図にプロットすると、結構うまいこと補完できていそうだった。また、Hokanどうしを見比べてみると、oriと比較した場合と比べて分布が締まって見える。
・BとCに関しては割愛。
おわり。