【Python】dataframeを数字に変換したい。
・お題:pandasのdataframeで、本来数字が入るべきところにエラーの文字列が入っており、無視したいのに数字として処理できない。文字列をNaNに変換し、数字として扱いたい。
・データセットを作成する。
import pandas as pd
df=pd.DataFrame({"A":[1,2,3,4,5],
"B":[1.2, 2.3, 3.4, 4.5, 5.6],
"C":[6,"seven","eight",9,10],
"D":[6.5,"n.r",8.9,"n.z","j.j"],
"E":["a","b","c","d","e"]})
これでdfは以下になる。
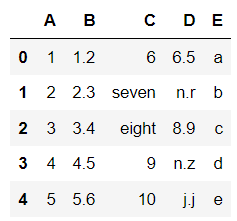
・各列のデータ型を見てみる。
df.info()で以下が返ってくる。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 5 non-null int64
1 B 5 non-null float64
2 C 5 non-null object
3 D 5 non-null object
4 E 5 non-null object
dtypes: float64(1), int64(1), object(3)
memory usage: 328.0+ bytes
CDE列がobjectになっており、数字として認識されていないっぽい。
・非数字を数字(NaNとして欠損値処理)するには、pandasのto_numericメソッドを使う。きちんとしたことは、以下の公式サイトから確認していただきたい。
henkan=lambda x :pd.to_numeric(x,errors="coerce")
df2=df.apply(henkan)
とすると、df2は以下になる。
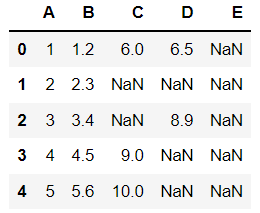
・各列のデータ型を見てみる。
df2.info()とすると、以下が返ってくる。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 5 non-null int64
1 B 5 non-null float64
2 C 3 non-null float64
3 D 2 non-null float64
4 E 0 non-null float64
dtypes: float64(4), int64(1)
memory usage: 328.0 bytes
CDE列が数字(float64)に変換された。
おわり。