【KNIME】もっとクラスタリングしてみたい(k-Medoids)
・先のノード検索の際に出てきたk-Medoidsを使ってみる。
・細かいことは分からないが、k-Meansのように仮想の重心を置くのではなく、データの中から重心に相当するものを選抜することでクラスタリングをするらしい。
・特長は外れ値に比較的強いことだとか。
・試しに使ってみるにしても、k-Meansとは勝手が違い、データ間の距離を定義してやる必要があるらしい。
・そこで、距離を定義するノードを差し挟み、クラスタリングを実施した(下図)。

・Numeric Distancesノードは、データ間の距離を算出するノード、ということになる。このノードでは、様々な定義の距離を算出することができるらしい(下図)。

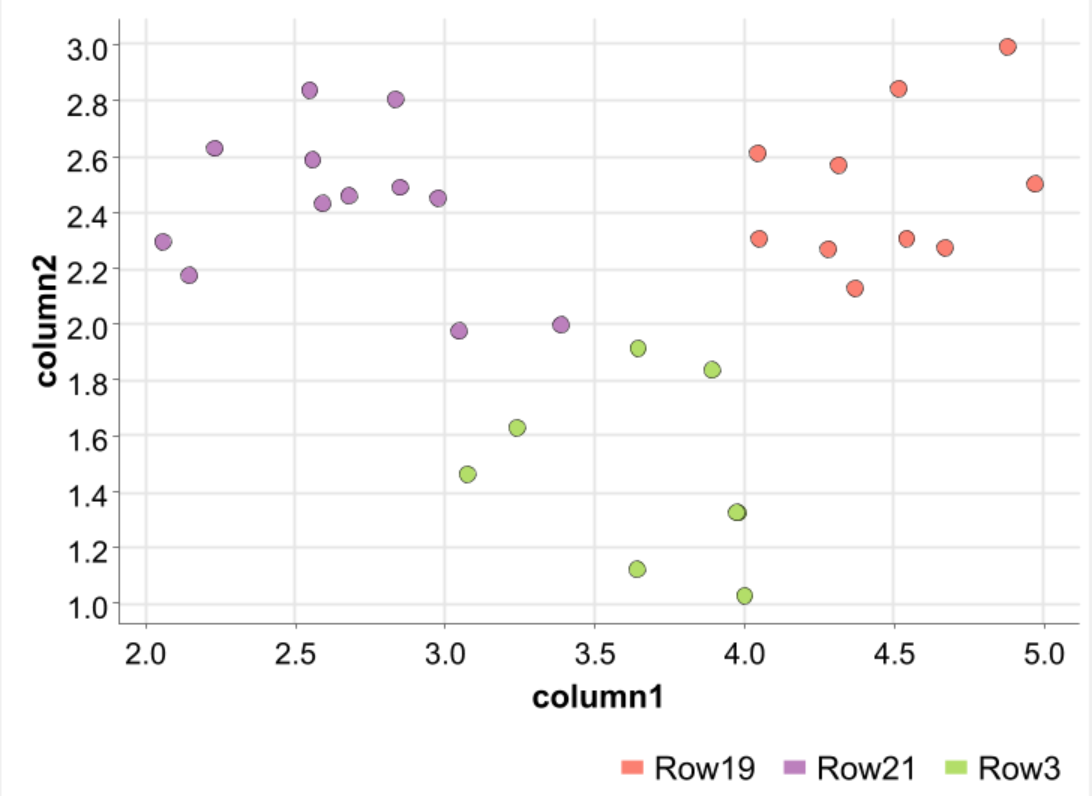
・このフローでクラスタリングし、散布図を描画すると、以下のようになった。
・距離の算出は、Distance Matrix Calcuratesノードを使うこともできるらしい。
・他の手法とどう使い分けるか、違いを理解したいところ。
終わり。